Multiple machine learning algorithms could be used in the same model to improve the prediction obtained by any of the algorithms used on its own. This is also known as an ensemble method.
There are many resources on the internet explaining what ensemble methods are so it will not be repeated here.
A Youtube video by Marios Michailidis on stacking:
https://www.youtube.com/watch?v=enEerl0feRo
An article on Analytics Vidhya:
https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-for-ensemble-models/
In this post, one ensemble method known as stacking will be explored. A combination of Linear Regression and a Random Forest Regressor will be used as base level models in a two level stack.
The dataset used is taken from the Concrete Compressive Strength Data Set from the UCI Machine Learning Repository.
Reference
https://archive.ics.uci.edu/ml/datasets/Concrete+Compressive+Strength
(Accessed on 10 Feb 2020)
“Reuse of this database is unlimited with retention of copyright notice for Prof. I-Cheng Yeh and the following published paper: I-Cheng Yeh, “Modeling of strength of high performance concrete using artificial neural networks,” Cement and Concrete Research, Vol. 28, No. 12, pp. 1797-1808 (1998).”
In this example, a small test set of seven samples have been extracted from the main dataset. These samples will be used to assess the ensemble model and have been omitted from the main dataset.

Let us consider the block of code below for creating an interactive data visual. The code shown would not start from Line 1 or have continuous Line numbering as with previous post, as some comments/notes present in the code has been omitted for simplicity sake.
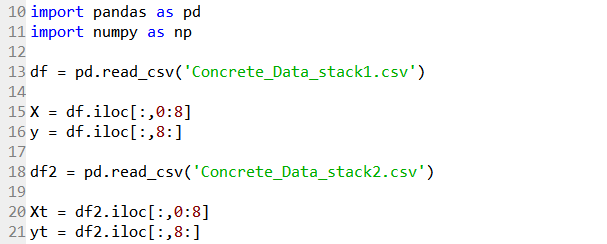
Line 10 imports the Pandas module for data handling, and Line 11 imports the Numpy module that will be used later on. Line 13 reads the edited .csv file downloaded from the repository, with the selected seven samples removed, as a Pandas dataframe. The data is then split into X (feature variables) and y (target variable) in Line 15 and 16. Likewise for the seven test samples in Line 18 to 21.
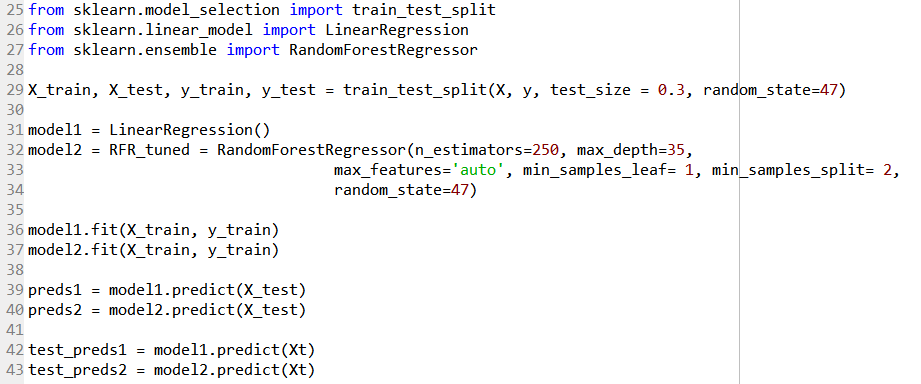
Line 25 to 27 import the required functions from the sklearn module. Line 29 then splits the data into a training set, and a validation set. The test_size of the validation set is fixed as 30% of the full data set, while the random_state value act as a seed value to make the result reproducible to follow by fixing a particular state.
Line 31 creates a Linear Regression model, and Line 32 to 33 creates a Random Forest Regressor model (using tuned parameters from a previous post). This forms Level 0 of the stack.
Line 36 and 37 fits the respective models with the training set. Line 39 and 40 uses the fitted data to predict the target variable in the validation set. Line 42 and 43 uses the fitted data to predict the target variable in the test set (i.e. the seven samples that were separated earlier).

Line 45 then combines the predicted target variables from the validation set as a two-column np array. Line 46 combines the the predicted target variables from the test set likewise.

Line 53 creates a meta model (which forms Level 1 of the stack) using an Random Forest Regressor. Line 54 fits the predicted target variables of the validation set against its true values. In a way, this attempt to assess how much the prediction deviates from the true target variable. Line 55 then uses this deviation (i.e. error) to “compensate” for the prediction made for the test set. Line 56 then calculates the R-squared (R^2) value of this two level stacked model, which is 0.9101473807695799.
How does this fare against a single Random Forest Regression model?

Line 65 to 74 fits the Random Forest Regressor to the training data, followed by predicting the seven samples in the test data. The R^2 thus obtained is 0.9006710447409739.
Although the Random Forest Regressor is an ensemble method in itself, in this case a two level stack consisting of a Linear Regressor and Random Forest Regressor as the base level did provide a small improvement of the R^2 value by approximately 1%.
Is there any way to make the above codes more concise and elegant? Feel free to comment.
